Researchers can store 215 petabytes of data on a single gram of DNA
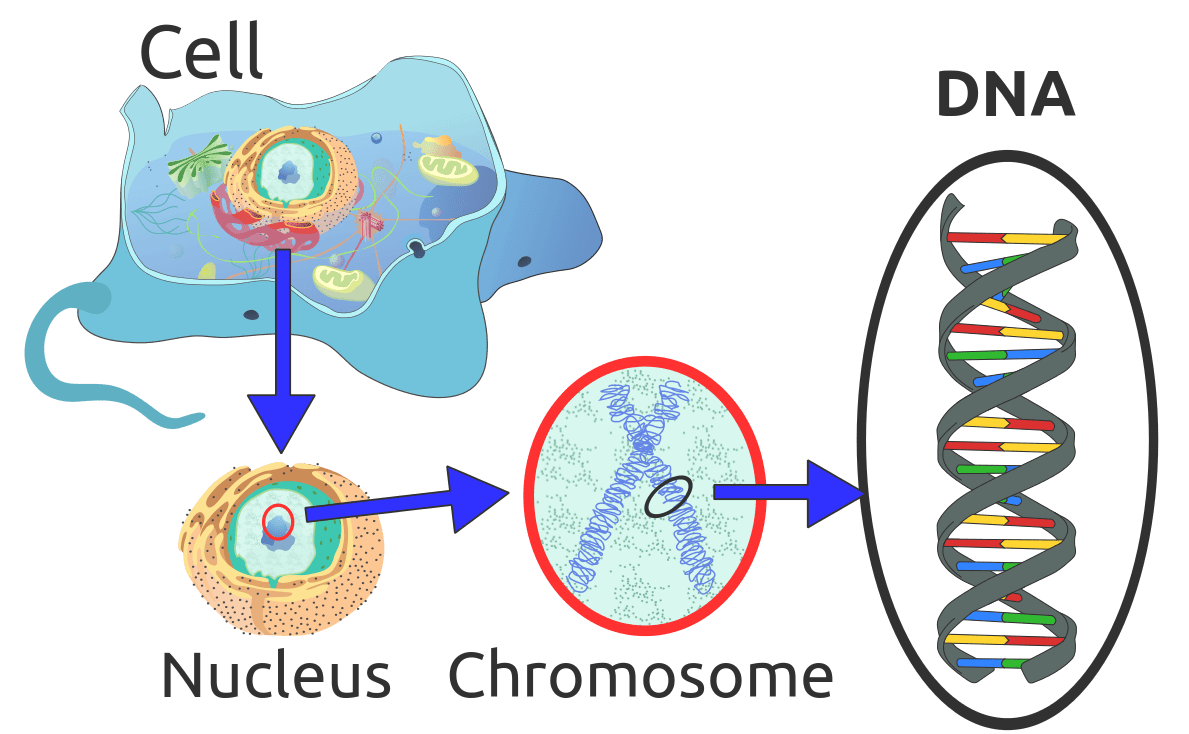
This could very well be the future of storage. Researchers at Columbia University and the New York Genome Center created an algorithm for streaming video on cellphone that can unlock DNA’s (almost) full storage potential. With this algorithm, researches can store 215 petabytes (200234353.54 Gigabytes or 215000 Terabytes) in a single gram of DNA. Given that DNA does not degrade in quality like tape or CD, what you store in DNA will be safe forever. Will this become the key aspect of storage in far future, we can only wait and see!

Cost is a major barrier here. Researchers had spent $7000 to synthesize DNA needed to archive just 2MB of data and another $2000 to read data from DNA. The price will be reduced if lower quality molecules can be produced and if DNA Fountain is used to fix molecular errors. The advantage though is that DNA can last for thousands of years if kept in cool and dry place. Look at the DNA extracted from ancient fossils that are more than hundred thousand years old.
“DNA won’t degrade over time like cassette tapes and CDs, and it won’t become obsolete—if it does, we have bigger problems,” said study coauthor Yaniv Erlich, a computer science professor at Columbia Engineering, a member of Columbia’s Data Science Institute, and a core member of the NYGC.
Erlich and his colleague Dina Zielinski, an associate scientist at NYGC, chose six files to encode, or write, into DNA: a full computer operating system, an 1895 French film, “Arrival of a train at La Ciotat,” a $50 Amazon gift card, a computer virus, a Pioneer plaque and a 1948 study by information theorist Claude Shannon.
To test this, the researchers compressed the files into a master file, split the file into short strings of binary code (1s and 0s). Fountain code error correction algorithm is then used to covert these strings into droplets. Once the droplets are created, researchers mapped ones and zeros in each droplet to four nucleotide bases in DNA (A, G, C, T). Nucleotide is a basic structural unit and building block for DNA. These nucleotides are hooked together to form DNA chain. A barcode is added to each droplet for later identification and the algorithm also removed letter combinations that are known to create errors.
72,000 strands of DNA was created this way and each strand was 200 bases long. This was sent to Twist Bioscience (DNA-Sysnthesis startup in San Francisco) to change digital data into biological data.
Twist Bioscience created vial containing speck of DNA molecules in two weeks time and sent it back to Columbia University. To retrieve the files from DNA strands, modern DNA sequencing technology was used to translate genetic code to binary code. The retrieved data, when compared to original data had no errors. To create multiple copies of this stored data, all that is to be done is take the DNA sample and multiply it using polymerase chain reaction technique.
Here is a movie that was stored and retrieved from DNA molecules.